#88
#fish_length는 물고기의 무기
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
#fish_weight는 물고기의 무게
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]import numpy as np
A = np.column_stack(([1,2,3],[4,5,6]))
fish_data = np.column_stack((fish_length, fish_weight))
print(fish_data[:5])
print(np.ones(5))[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]]
[1. 1. 1. 1. 1.]
numpy의 column_stack 함수
numpy의 column_stack() 함수는 전달받은 리스트를 일려로 세운다음 차례대로 나란히 연결한다. 즉, 2차원배열로 만든다.
numpy의 concatenate() 함수
numpy의 concatenate()함수는 첫번쨰 차원을 따라 배열을 연결한다.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
print(fish_target)[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
trans_test_split() 함수
앞에서는 numpy배열의 인덱스를 직접 섞어서 훈련세트와 테스트세트로 나누었는데 이젠 사이킷런의 train_test_split()함수를 사용하여 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 준다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state=42)이 함수를 사용하여 train_input, train_target, test_input, test_target 4개의 배열이 반환된다.
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
print(test_target)(36, 2) (13, 2)
(36,) (13,)
[1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
도미 와 빙어의 비율이 2.5:1인데 현재 비율은 3.3:1이다.
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)
print(test_target)[0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
stratify 매개변수에 타깃데이터를 전달하면 클래스 비율에 맞게 데이터를 나눈다.
빙어가 하나 늘은 것을 알 수 있다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
print(kn.predict([[25,150]]))1.0
[0.]
test 결과 1.0이 나왔으므로 훈련이 잘됐다고 알 수 있었다. 그래서 이번엔 25cm의 길이와 150kg을 가진 도미 데이터를 넣고 결과를 확인해봤는데 0(빙어)이 나왔다.
산점도로 확인해보자
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25,150,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
도미데이터와 가까워 보이는데 왜 빙어데이터에 가깝다고 본 것일까?
k-최근접이웃은 주변의 샘플 중에서 다수의 클래스를 예측으로 사용한다. 즉 이 데이터 주변이 도미보다 빙어의 샘플이 더 많았던 것이다.
확인해보자
distances, indexes = kn.kneighbors([[25,150]])
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25,150,marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()KNeighborsClassifier 클래스에서 kneighbors()메서드를 사용하여 이웃들까지의 거리와 인덱스를 반환하자 기본적으로 n_neighbors의 기본값은 5이므로 이웃의 개수는 5개의 이웃이 반환된다.

print(train_input[indexes])
print(train_target[indexes])
print(distances)[[[ 25.4 242. ]
[ 15. 19.9]
[ 14.3 19.7]
[ 13. 12.2]
[ 12.2 12.2]]][[1. 0. 0. 0. 0.]]
[[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlim((0,1000)) # x의 범위를 1000으로 만든다.
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
산점도가 거의 일직선으로 나타난다. x축과 y축의 범위를 동일하게 맞추었더니 모든 데이터가 수직으로 늘어선 형태가 되었다.
이런 데이터는 x축보단 y축 즉, 무게의 영향이 크다.
두 특성(길이와 무게)의 범위가 다르다는 것은 두 특성의 스케일이 다르다는 것과 같다.
신발 10mm 늘어나는 것과 키 1cm가 늘어나는 것은 많이 다르다고 생각될 것이다.
k-최근접 이웃은 샘플간의 거리에 영향을 많이 받는다.
따라서 이 알고리즘을 제대로 사용하려면 특성값을 일정한 기준으로 맞춰 특성값을 일정한 기준으로 맞춰줘야한다.
이러한 작업을 데이터 전처리 라고 한다.
데이터 전처리
데이터 전처리 방법 중 하나는 표준점수를 이용한 것이다.
표준점수란 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교할 수 있다.
표준점수는 값에서 평균을 빼고 표준편차를 나누어주면 된다.
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
print(mean,std)[ 27.29722222 454.09722222] [ 9.98244253 323.29893931]
axis=0은 한 열을 말한다. axis=1일경우 한 행(하나의 샘플 값)을 말한다.
np.mean()함수는 평균을 계산하고, np.std()함수는 표준편차를 계산한다. 특성마다 값의 스케일이 다르기 때문에 평균과 표준편차는 각 특성별로 해야한다.
axis=0일 때, 행을 따라 각 열의 통계값을 계산한다.
train_scaled = (train_input - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(25,150,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
값 25, 150도 똑같이 전처리를 해주어야하는데 안해줘서 나타난 것이다.
전처리를 해주자
new = ([25,150]-mean)/std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0],new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()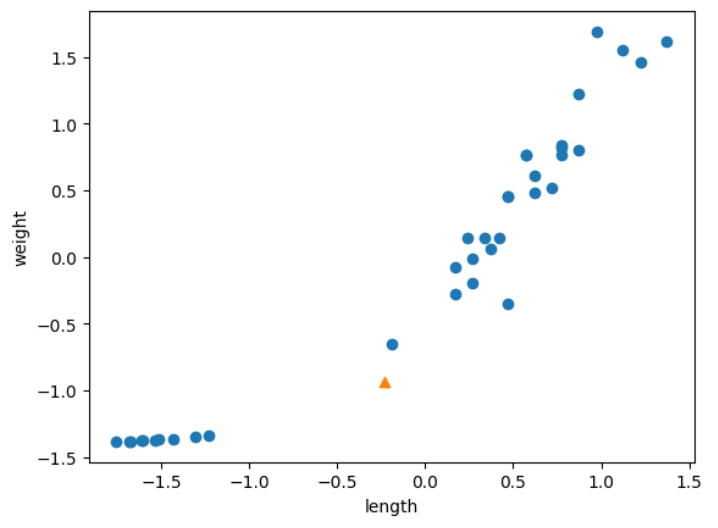
kn.fit(train_scaled,train_target)
test_scaled = (test_input - mean) / std
kn.score(test_scaled, test_target)
print(kn.predict([new]))1.0
[1. ]
점수는 1로 잘 학습된 것을 알 수 있었고 문제에 대한 예측도 1로 도미로 잘 예측했다.
실습
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0],train_scaled[:,1])
plt.scatter(new[0],new[1],marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1],marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
'STUDY' 카테고리의 다른 글
| [AI] 특성공학과 규제 (0) | 2022.11.06 |
|---|---|
| [AI] 선형회귀 (0) | 2022.11.06 |
| [AI] k-최근접 이웃 회귀 (1) | 2022.11.06 |
| [AI] 훈련 세트와 테스트 세트 (0) | 2022.10.19 |
| Discord 봇 (0) | 2020.04.23 |